Primeros pasos con Apache Cassandra



Apache Cassandra es una base de datos NoSQL (Not-Only SQL) distribuida de código abierto. Es la elección perfecta cuando necesitamos escalabilidad y gran disponibilidad de los datos sin comprometer el rendimiento. Proporciona un robusto soporte para clusters que pueden llegar a abarcar multiples datacenters.
Cassandra posee una arquitectura sin amo, en la cual todos los nodos del data center actúan por igual. Los datos se distribuyen automáticamente entre todos los nodos que se encuentran en un "anillo" o cluster.
El factor de replicación es configurable, almacenando copias redundantes de datos en cada nodo. De esta manera si perdemos un nodo, la información sigue estando disponible en los otros.
La escalabilidad es lineal. La capacidad puede ser incrementada tan solo añadiendo nuevos nodos al cluster. Es decir, si dos nodos puede ejecutar 100.000 operaciones por segundo, cuatro nodos iguales podrán con 200.000 operaciones por segundo.
El modelo de datos de Cassandra consiste en filas particionadas que se almacenan en tablas con un nivel de consistencia configurable. Las tablas se indexan por medio de llaves. El primer componente de la llave primaria de una tabla, primary key, es la llave de partición, partition key. Estas son definidas por las columnas que definen una entrada en la tabla. Dentro de cada partición, las filas se almacenan siguiendo el orden de las columnas restantes que conforman la llave, estas son la llamadas clustering keys.
El nivel de consistencia se refiere a como se sincronizan y actualizan replicas de las filas de datos a lo largo del cluster (nodos). El nivel de consistencia de datos puede ser establecido en cada lectura o escritura en función de las necesidades de velocidad y precisión.
La interfaz primaria y por defecto para comunicarnos con Cassandra es CQL (Cassandra Query Language). Su sintaxis es muy similar a SQL (Structured Query Language) con la principal diferencia de que Cassandra no soporta joins o subqueries. Para ejecutar sentencias CQL, Cassandra viene con una herramienta por consola llamada cqlsh.
He de mencionar que en las primeras versiones de Cassandra la comunicación se realizaba por medio de APIs algo complejas que han quedado obsoletas frente a las ventajas que ofrece CQL, para el cual existe una amplia documentación soportada por DataStax.
Probando Cassandra en una máquina virtual
Para empezar a probar Cassandra DataStax pone a nuestra disposición una máquina virtual funcional out-of-the-box con la última version de Cassandra que podemos añadir a VMWare o VirtualBox. Para ello descargaremos el archivo: Cassandra OVA y lo importaremos a nuestro sistema de virtualización preferido. Es necesario configurar el acceso en red para poder acceder a la máquina virtual.
Una vez tengamos instalada la máquina virtual, al arrancar podremos ver en consola la dirección IP por la cual podremos acceder a la interfaz web que la máquina trae consigo.
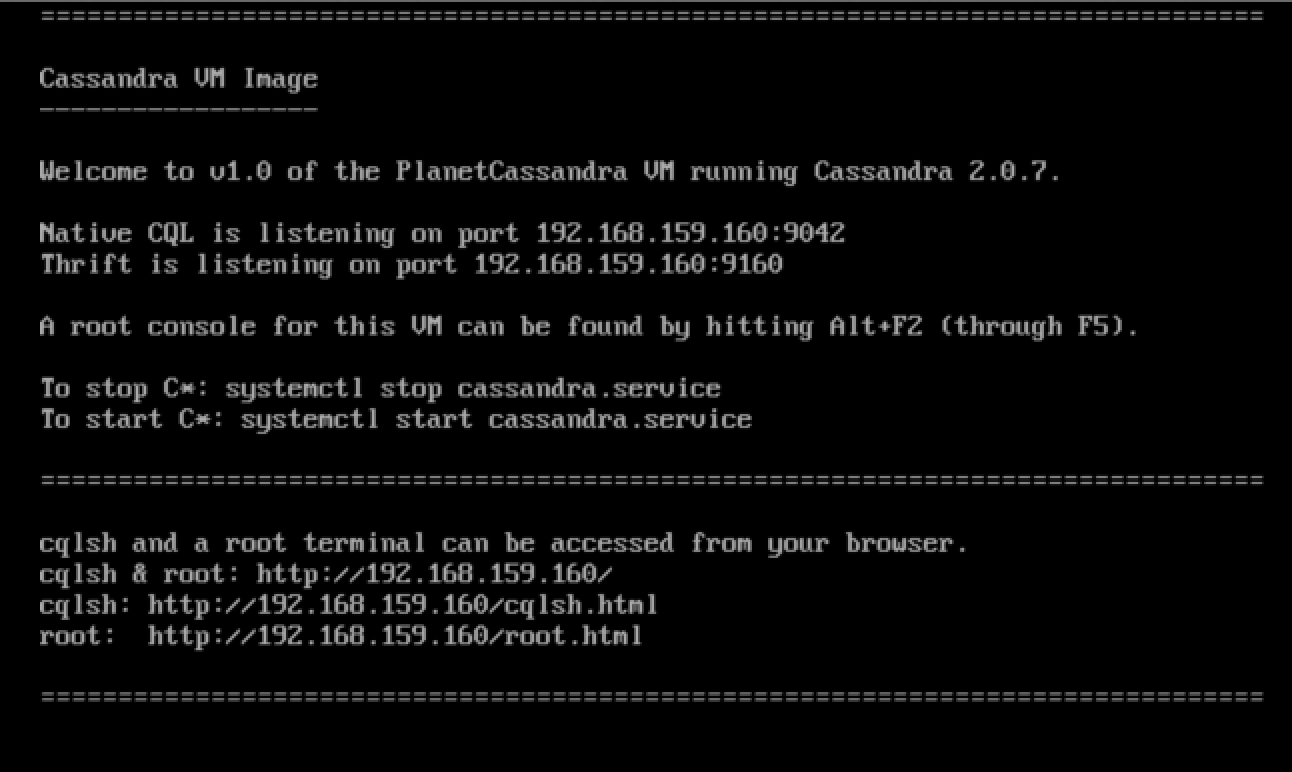
En este caso la IP asignada es 192.168.159.160, para lo que voy a mi navegador y accedo a la URL: http://192.168.159.160.
Aquí tendremos una consola con el superusuario de la máquina y otra con la interfaz cqlsh. En esta ultima podemos probar las siguientes sentencias para crear un keyspace, una tabla de usuarios e introducir y leer unas cuantas entradas:
Empezamos creando el keyspace, que es donde se almacenan todos los datos de nuestra aplicación, es similar a un schema en bases de datos relacionales como MySQL.
CREATE KEYSPACE geeky WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
Si ahora ejecutamos:
DESC KEYSPACES;
Podremos ver:
system videodb system_traces geeky
Indicamos que queremos usar el keyspace geeky:
USE geeky;
Y creamos la tabla de usuarios:
CREATE TABLE users (
firstname text,
lastname text,
email text,
organization text,
PRIMARY KEY (lastname));
Para obtener más información de la tabla que acabamos de crear simplemente ejecutamos:
DESC SCHEMA;
Probamos a insertar unos cuantos usuarios:
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Mario', 'Perez', 'mario@geekytheory.com', 'Geeky Theory');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Alex', 'Esquiva', 'alex@geekytheory.com', 'Geeky Theory');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Miguel', 'Catalan', 'miguel@geekytheory.com', 'Geeky Theory');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Dachi', 'Gogotchuri', 'dachi@geekytheory.com', 'Geeky Theory');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Kolduis', 'Panda', 'kolduis@geekytheory.com', 'Geeky Juegos');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Osmary', 'Guevara', 'osmary@geekytheory.com', 'Geeky Theory');
INSERT INTO users (firstname, lastname, email, organization) VALUES ('Aldo', 'Ros', 'aldo@geekytheory.com', 'Geeky Theory');
Si ahora ejecutamos:
SELECT * FROM users;
Veremos:
lastname | email | firstname | organization
------------+-------------------------+-----------+--------------
Catalan | miguel@geekytheory.com | Miguel | Geeky Theory
Ros | aldo@geekytheory.com | Aldo | Geeky Theory
Perez | mario@geekytheory.com | Mario | Geeky Theory
Guevara | osmary@geekytheory.com | Osmary | Geeky Theory
Panda | kolduis@geekytheory.com | Kolduis | Geeky Juegos
Gogotchuri | dachi@geekytheory.com | Dachi | Geeky Theory
Esquiva | alex@geekytheory.com | Alex | Geeky Theory
(7 rows)
Para obtener una entrada en concreto probamos con la sentencia:
SELECT * FROM users WHERE lastname= 'Panda';
lastname | email | firstname | organization
----------+-------------------------+-----------+--------------
Panda | kolduis@geekytheory.com | Kolduis | Geeky Juegos
(1 rows)
Vamos a probar con UPDATE.
Cassandra nunca lee antes de escribir, no comprueba si los datos ya existen al hacer un INSERT, por lo tanto UPDATE e INSERT sobreescriben las columnas de una entrada sin importar los datos ya almacenados.
UPDATE users SET organization='Geeky Juegos' WHERE lastname='Catalan';
Ahora si hacemos:
SELECT * FROM users WHERE lastname='Catalan';
lastname | email | firstname | organization
----------+------------------------+-----------+--------------
Catalan | miguel@geekytheory.com | Miguel | Geeky Juegos
(1 rows)
Probamos a borrar una entrada:
DELETE from users WHERE lastname = 'Ros';
Para comprobar si el usuario ha sido borrado volvemos a consultar la tabla:
SELECT * FROM users;
Y hasta aquí las primeras impresiones de Cassandra. Como ya he mencionado es una base de datos NoSQL sencilla de usar y potente. Su velocidad y robustez, y la facilidad con la que se pueden crear datacenters o ampliar los ya existentes hacen que muchos proyectos de BigData y empresas utilicen Cassandra hoy en día.
Fuentes: