Cómo crear un clúster de servidores con Apache Spark


Apache Spark tiene un potencial impresionante. Como ya dije en el artículo de introducción a Spark, es una herramienta muy utilizada actualmente en Big Data y machine learning y que a lo largo de estos años será mejorada. En este tutorial vamos a aprender a montar un clúster de servidores con Apache Spark con el fin de sacar partido a su potencial de computación distribuida.
¿Qué es un cluster?
Un cluster es un sistema basado en la unión de varios servidores que trabajarán de forma paralela como si de uno solo se tratara, es decir, tenemos un servidor formado por otros servidores. Podemos tener un cluster de 2, 10, 20 ó 100 servidores. Cuantos más servidores tengamos, más potencia de hardware estará disponible. Gracias a que Apache Spark hace un uso eficiente de las máquinas que formen un cluster, el sistema será escalable y realizará un correcto balanceo de carga.
Creación del cluster
Para crear un cluster podemos hacer uso de servidores reales o máquinas virtuales en local. Debido a que no tengo servidores disponibles para este fin y tampoco quiero alquilarlos, voy a hacerlo con máquinas virtuales, por lo que utilizaré:
- Herramienta de virtualización: VMware. Podéis ver cómo instalarlo en este tutorial. Si no queréis usar VMware, también podéis hacerlo con VirtualBox, que funciona igualmente.
- Sistema operativo: Ubuntu 14.04. Podéis ver cómo instalarlo en este tutorial.
Crear un cluster de servidores en local con máquinas virtuales no tiene sentido porque se pierde rendimiento, pero como el objetivo es aprender, no hay problema en este caso.
Requisitos
Crear un cluster de servidores Apache Spark es muy parecido a como se crearía un único servidor de Spark. Lo único que hay que hacer para añadir máquinas es poner sus direcciones IP en un archivo de configuración. Sin embargo, hay que tener un determinado software instalado:
- Java: se puede utilizar tanto la versión 7 como la 8.
- Scala: se instalará la última versión.
- Acceso remoto por SSH entre máquinas.
- Apache Spark pre-compilado para Hadoop.
Arquitectura de un cluster de Apache Spark
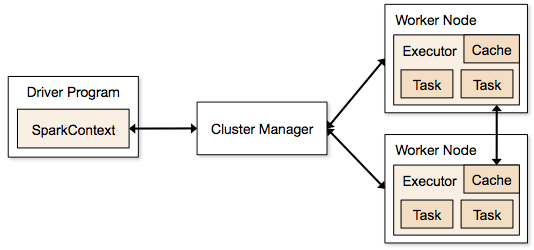
En la arquitectura de un cluster montado con Apache Spark se puede observar que existen distintos agentes. El primero de ellos es el controlador. Tras esto, encontramos el cluster manager y finalmente los workers. De una manera muy resumida, el manager hace las veces de maestro y el worker de esclavo. Conviene conocer algunos términos:
- Aplicación: programa desarrollado sobre Spark por un programador.
- Controlador del programa (driver program): es el proceso que ejecuta la función main de la aplicación.
- Cluster manager: servicio externo utilizado para gestionar los recursos de los workers.
- Worker: nodo (servidor) que puede ejecutar código Spark.
- Task: operaciones (tareas) a realizar por un worker.
Máquinas virtuales
Todas las máquinas virtuales deben tener software en común, que es el que he mencionado antes: Java, Scala y Spark. Al tener Ubuntu recién instalado, habrá que configurar el sistema para tener el software disponible. Sin embargo, no queremos configurarlo todo cada vez para cada máquina, por lo que haremos uso de la función de clonado de VMware para configurar un único servidor y luego clonarlo.
Paso 1
El primer paso es crear la máquina Ubuntu. Yo la llamaré spark-master, para saber en qué máquina estoy trabajando. He dejado toda la configuración por defecto excepto la memoria RAM, que le he puesto 2GB. Cada uno que ponga lo que su ordenador le deje.
Cuando ya se haya instalado el sistema operativo por completo, veremos algo parecido a lo siguiente:
Los pasos que vienen a continuación se harán en la máquina ubuntu-spark-master.
Paso 2
En este paso se instalará Java. Vale tanto la versión openJDK como la de Oracle. En este caso se va a instalar Java 8 de Oracle. Para ello, hay que introducir los comandos que se mostrarán a continuación. Antes de nada, conviene actualizar el sistema: sudo apt-get update sudo apt-get upgrade -yTras el paso anterior, se procede a instalar Java: sudo apt-add-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installerSi todo va bien, deberíamos tener el siguiente resultado al comprobar la versión instalada: $ java -version java version "1.8.0_45"
Paso 3
Este tercer paso va a consistir en instalar Scala. No lo voy a explicar de nuevo porque ya hice un tutorial de instalación, por lo que os dejo el enlace con las instrucciones.

Paso 4
Para comenzar con el cuarto paso apagamos la máquina virtual, ya que no se pueden clonar máquinas si la de origen está encendida. Una vez esté apagada, click con el botón derecho en el nombre de la máquina y dentro de "Manage", seleccionar "clonar".
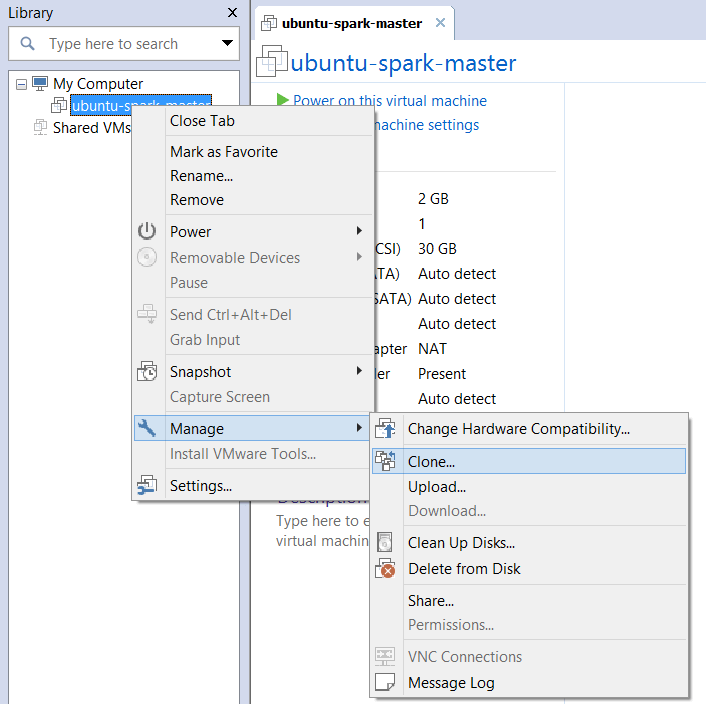
El tipo de clonación va a ser "linked" o "enlazada" y el nombre de la nueva máquina virtual: ubuntu-spark-worker-node.
Paso 5
En este paso vamos a obtener las direcciones IP de ambas máquinas porque van a ser necesarias durante el proceso. De esta manera, las dejamos apuntadas para el tutorial y no tenemos que estar siempre comprobándolas con ifconfig:
- ubuntu-spark-master: 192.168.107.128
- ubuntu-spark-worker-node: 192.168.107.129
Paso 6
Apache Spark necesita acceder por SSH a las máquinas, pero sin contraseña, por lo que tendremos que crear una clave para permitirle establecer la conexión. En la máquina ubuntu-spark-worker-node se introduce este comando: sudo apt-get install openssh-serverEn la máquina ubuntu-spark-master generamos una clave RSA para el acceso remoto a los workers: ssh-keygenPara tener acceso a los workers sin contraseña, la clave RSA generada en el master debe ser copiada en cada uno de los workers. Por lo tanto, en la máquina ubuntu-spark-master se ejecuta el siguiente comando: ssh-copy-id -i ~/.ssh/id_rsa.pub usuario_worker_1@IP.DEL.WORKER.1 ssh-copy-id -i ~/.ssh/id_rsa.pub usuario_worker_2@IP.DEL.WORKER.2 ssh-copy-id -i ~/.ssh/id_rsa.pub usuario_worker_3@IP.DEL.WORKER.3Teniendo en cuenta lo anterior y sabiendo que únicamente hay un worker y su dirección IP es 192.168.107.129 con nombre de usuario mario, en ubuntu-spark-master se introduce el siguiente comando: ssh-copy-id -i ~/.ssh/id_rsa.pub mario@192.168.107.129
Paso 7
En este paso se va a descargar Apache Spark desde su página web. A día de hoy, la versión más reciente es la 1.4.0 y se va a descargar el paquete pre-compilado para Apache Hadoop 2.6 y posteriores. Al estar pre-compilado el proceso será más rápido. La descarga de Apache Spark hay que realizarla en todas las máquinas; tanto master como workers.
Una vez descargado, se descomprime en la carpeta /home/usuario, quedando en mi caso en la ruta /home/mario/spark-1.4.0-bin-hadoop2.6. Para probar que todo funciona correctamente, dentro de la carpeta bin ejecutamos el comando ./spark-shell y tendremos como resultado una consola de Spark.
Paso 8
El octavo paso consiste en la configuración de Apache Spark, en la que indicaremos quién es el nodo master y quiénes son los workers.
- Configuración de los esclavos.
Abrimos la carpeta de Spark en ubuntu-spark-master. Dentro de la carpeta conf hay un archivo llamado slaves.template, el cual vamos a renombrar a slaves. Este archivo contiene las direcciones IP de los nodos esclavos (workers), por lo que comentamos todas las líneas con '#' y añadimos la IP de nuestro ubuntu-spark-node-worker para que finalmente quede así: # A Spark Worker will be started on each of the machines listed below. # localhost 192.168.107.129Copiamos este archivo en la misma ruta del ubuntu-spark-node-worker.
- Configuración del entorno Apache Spark.
Abrimos la carpeta de Spark en ubuntu-spark-master. Dentro de la carpeta conf hay un archivo llamado spark-env.sh.template, el cual vamos a renombrar a spark-env.sh. Añadiremos las siguientes líneas de configuración: export SPARK_MASTER_IP= IP.UBUNTU.SPARK.MASTER # En mi caso es la 192.168.107.128 export SPARK_WORKER_CORES=1 # Número de cores que se ejecutan en la máquina export SPARK_WORKER_MEMORY=800m # Memoria total que un worker tiene disponible export SPARK_WORKER_INSTANCES=2 # Número de procesos worker por cada nodoIgual que con el archivo slaves, copiamos este archivo a todos los nodos dentro de la misma ruta. En este caso a ubuntu-spark-node-worker.
Paso 9
En este último paso haremos una prueba de funcionamiento para ver que todo está configurado correctamente. Para ello, ejecutaremos algunas operaciones.
- Paso 9.1: Probar la versión local
Dentro de la carpeta bin se ejecuta el siguiente comando para calcular el número Pi con Spark: ./run-example SparkPiSi todo va bien, debe mostrar por pantalla el valor de Pi.
- Paso 9.2: Probar el cluster
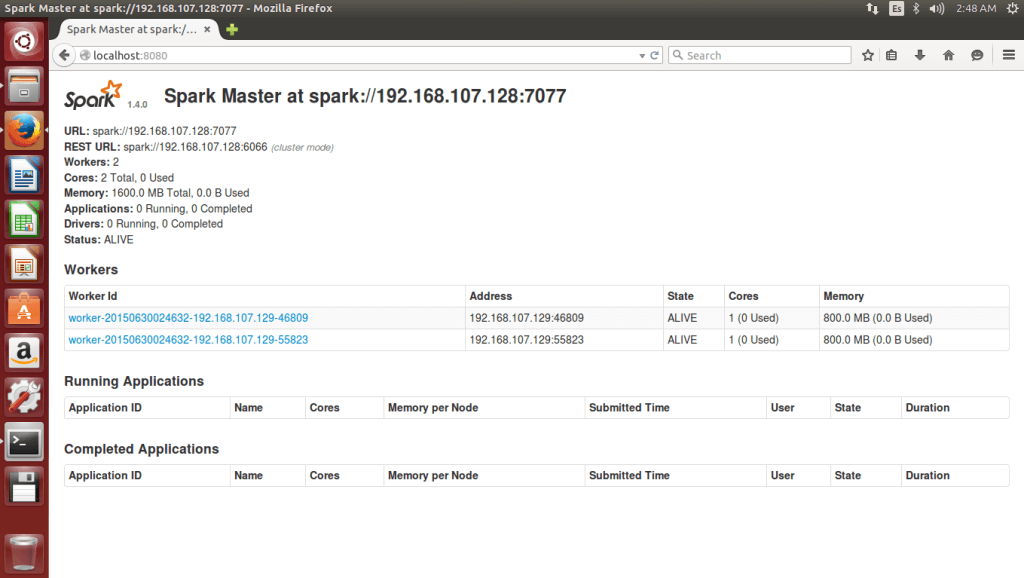
Dentro de la carpeta sbin tenemos varios ejecutables: Comando para iniciar el cluster: ./start-all.shComando para detener el cluster: ./stop-all.sh Tras iniciar el cluster, navegamos desde spark-node-master a localhost:8080 para ver el panel web, en el que deberíamos encontrar dos nodos worker:
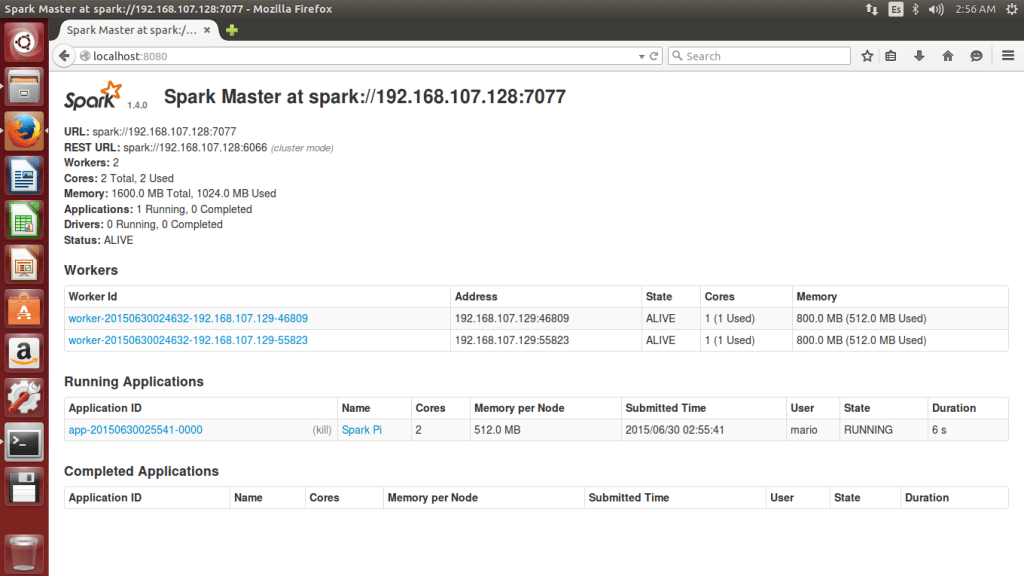
En el ejemplo de antes se ha calculado el número Pi en una única máquina (apache-spark-master), pero ahora queremos lanzar ese cálculo a los workers del cluster. Para ello, utilizamos el siguiente comando dentro de la carpeta bin: MASTER=spark://IP.UBUNTU.SPARK.MASTER:7077 ./run-example SparkPi En mi caso, sería: MASTER=spark://192.168.107.128:7077 ./run-example SparkPiComo resultado, es posible observar en el panel web que se está ejecutando una aplicación en el cluster:
Si mientras se ejecuta el programa véis el comando top en la máquina ubuntu-spark-worker-node, podréis observar que se están ejecutando dos procesos java, que se corresponden con Apache Spark. Espero que os haya servido el tutorial. ¡Saludos!