Análisis de sentimientos en Twitter con Python y Apache Spark Streaming
Apache Spark es una de las herramientas más utilizadas para procesar Big Data y en este caso se usará para analizar el sentimiento de Tweets en tiempo real con Python.


Vivimos en un mundo en el que se envían millones de tweets por segundo, se suben millones de fotografías y vídeos a Instagram, se ven millones de vídeos en YouTube y se publican cada vez más datos en Internet.
El futuro son los datos: saber entenderlos, analizarlos y obtener conclusiones gracias a ellos. Sin embargo, esta no es una tarea sencilla porque hay que utilizar las tecnologías adecuadas para cada caso de uso, y eso es lo que vamos a hacer en este tutorial.
Qué necesitas para leer tweets en tiempo real y analizar sentimientos
En este tutorial aprenderemos a extraer datos de Twitter en tiempo real y haremos un análisis de sentimientos de todos los tweets que leamos de Twitter. Esto lo vamos a hacer utilizando varias herramientas:
- Apache Spark: se utiliza para el procesamiento distribuido de datos a través de clústers de ordenadores de una manera sencilla y elegante. Puede utilizarse con Java, Scala, R y Python. En este tutorial utilizaremos Python.
- Spark Structured Streaming: existen varias tecnologías para hacer streaming con Apache Spark: Spark Streaming y Spark Structured Streaming, que es la que vamos a utilizar en este tutorial debido a que usa DataFrames.
- Tweepy: es una librería que nos permitirá obtener los mensajes de Twitter publicados en tiempo real con Python.
- TextBlob: es una librería que permite el procesamiento del lenguage natural con Python (Natural Language Processing, NLP). Con esta sencilla librería podremos realizar el análisis de sentimientos en Python.
- Sockets: se publicará un socket en el que se enviarán los tweets capturados en tiempo real y del que leerá Spark Streaming.
- Aplicación de desarrollador de Twitter: para poder conectarnos a Twitter a través de Tweepy necesitaremos una cuenta de desarrolladores.
Cómo funciona el análisis de sentimientos
En análisis de sentimientos de un texto es básicamente el proceso de determinar la actitud o la emoción de la persona que lo ha escrito. Sin embargo, aunque pueda sonar fácil, es algo realmente complejo de realizar. A menos que cuentes con las herramientas adecuadas, claro.
Qué es la polaridad
Las emociones están relacionadas con los sentimientos, y la polaridad (positivo, negativo, neutral) es la medida de las emociones expresadas en una frase. Las frases, por lo general expresan dos tipos de evaluaciones: racionales y emocionales.
- Frases racionales: "el altavoz suena bien", "estoy feliz con este coche".
- Frases emocionales: "estoy muy enfadado con el servicio de atención al cliente", "este es el mejor teléfono que jamás ha existido".
Por lo general, la polaridad va de negativo (-1) a positivo (1) pasando por neutral (0). Lo neutral suele significar que no se ha expresado ningún sentimiento u opinión.
Qué es la subjetividad
Hay dos tipos de textos: subjetivos y objetivos. Los textos objetivos no contienen sentimientos explícitos, mientras que los textos subjetivos sí. Veamos dos ejemplos:
- La camiseta es bonita.
- La camiseta es blanca.
Podríamos decir que la primera frase expresa un sentimiento positivo mientras que la segunda frase es neutral. Pero además, podríamos decir que 'bonita' es más subjetivo que 'blanca'.
Flujo de la arquitectura entre Spark Structured Streaming y Twitter
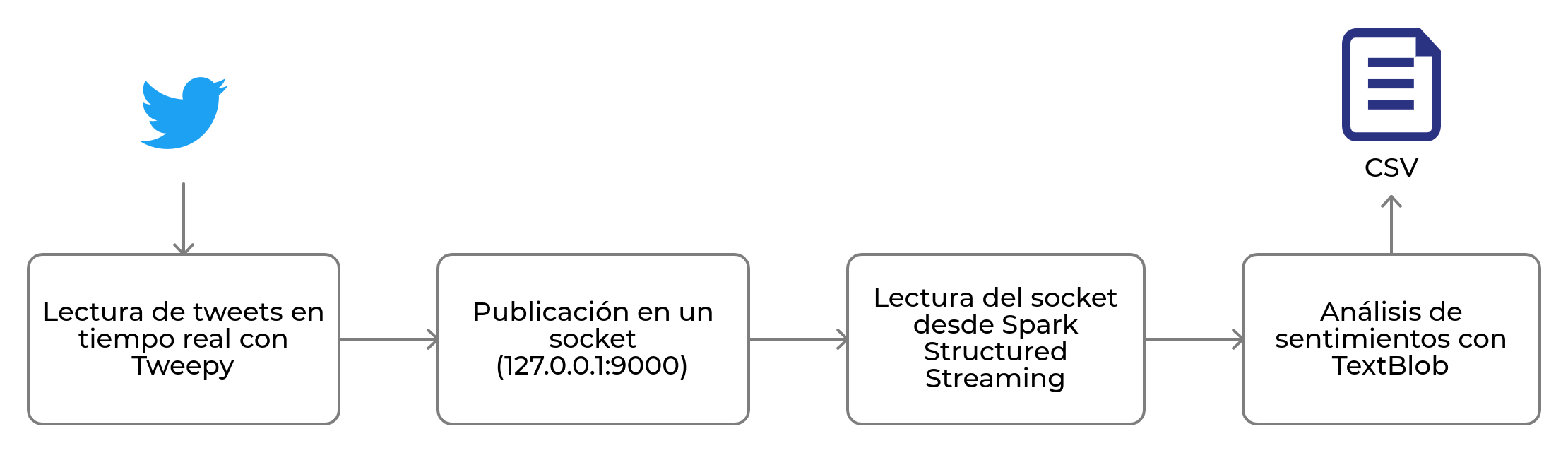
Tal y como se puede ver en la imagen, lo primero que haremos será conectarnos a Twitter para obtener los datos en tiempo real y enviarlos a Apache Spark Structured Streaming a través de un socket. Esta parte del código la puedes ver aquí.
A continuación, recibiremos esos tweets desde Apache Spark Structured Streaming y los analizaremos realizando un preprocesamiento y limpieza de los datos para seguidamente calcular la polaridad y subjetividad de cada mensaje.
Finalmente, guardaremos todos los mensajes analizados en un CSV con tres columnas: mensaje analizado, cálculo de la polaridad y cálculo de la subjetividad.
Preprocesamiento antes de analizar los sentimientos
A la hora de analizar datos con algoritmos es importante realizar un filtrado y limpieza de los mismos para evitar realizar malos análisis. Twitter envía los tweets en un formato que a veces mete ruido en Spark para que éste sea capaz de realizar un análisis de sentimientos. Por ejemplo, podríamos recibir este tweet en Spark:
RT @geekytheory: I love getting things done early in the day, feels like i have my life together #productivity #loveit
En este caso estamos viendo un retweet de un usuario a otro, por lo que se podría decir que tanto la palabra RT como el origen del tweet @geekytheory no nos interesan. Además, deberíamos eliminar las almohadillas hashtags.
Para ello, utilizaremos esta parte del código:
def stream_preprocessing(stream_messages):
return stream_messages.select(
explode(split(stream_messages.value, settings.ANALYSIS['TWEET_EOL'])).alias('message')) \
.withColumn('message', regexp_replace('message', r'http\S+', '')) \
.withColumn('message', regexp_replace('message', '@\w+', '')) \
.withColumn('message', regexp_replace('message', '#', '')) \
.withColumn('message', regexp_replace('message', 'RT', '')) \
.withColumn('message', regexp_replace('message', ':', ''))
Y acabaremos teniendo este resultado que ya puede ser analizado sin problema:
I love getting things done early in the day, feels like i have my life together productivity loveit
Desplegar aplicación de Apache Spark en un servidor Linux Ubuntu
A la hora de desplegar una aplicación de Apache Spark en un servidor Linux necesitamos que dicho servidor pueda ser autoadministrado, ya que tendremos que instalar varios programas dentro de ese mismo servidor. Para ello, utilizaré clouding.io, ya que me permite crear servidores Ubuntu en cuestión de minutos para hacer mis pruebas:
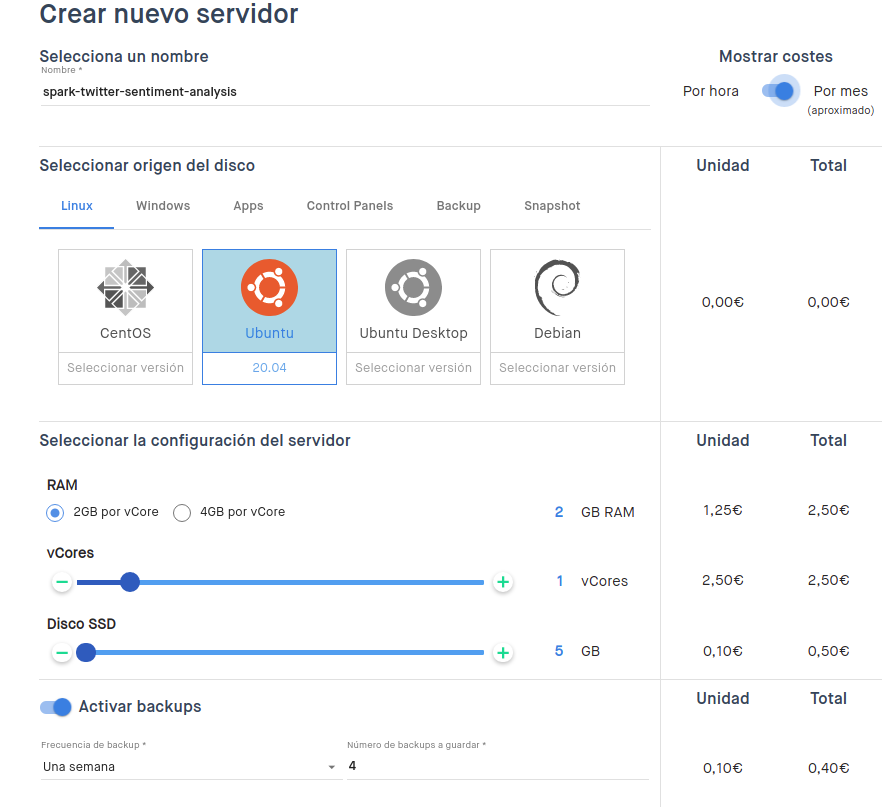
Como véis, se puede elegir cualquier tipo de configuración para la aplicación. En este caso utilizaré un Linux con 5GB de SSD, con un vCore y 2GB por cada vCore. Además, por si falla algo, he activado backups semanales que se guardarán durante 4 semanas.
Una vez hayamos creado el servidor, nos llegará un correo electrónico avisándonos de que ya está disponible y podremos entrar por SSH:
Para poder ejecutar nuestro analizador de sentimientos, lo primero que hay que hacer es instalar Java en la versión 8:
apt install openjdk-8-jre-headles
Además, tendremos que instalar pip en el servidor y algunas dependencias más:
apt install python3-venv python3-pip
A continuación descargaremos el repositorio del tutorial:
git clone https://github.com/GeekyTheory/Python-Spark-Structured-Streaming-Tutorial.git
Una vez hemos clonado el proyecto debemos instalar las dependencias:
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
Tras esto, seguiremos los pasos que nos indica el README.md del repositorio. Primero configuraremos el archivo settings.py:
cp settings.py.example settings.py
En este archivo [settings.py](http://settings.py) añadiremos nuestras claves de configuración de la aplicación de Twitter que habremos creado previamente.
Una vez hecho esto, simplemente vamos a abrir una nueva sessión SSH para ejecutar el código Python de streaming de Twitter y el de análisis de sentimientos con Apache Spark:
python twitter_streaming.py
python spark_streaming_sentiment_analysis.py
¡Somos capaces de analizar miles de tweets sin despeinarnos!
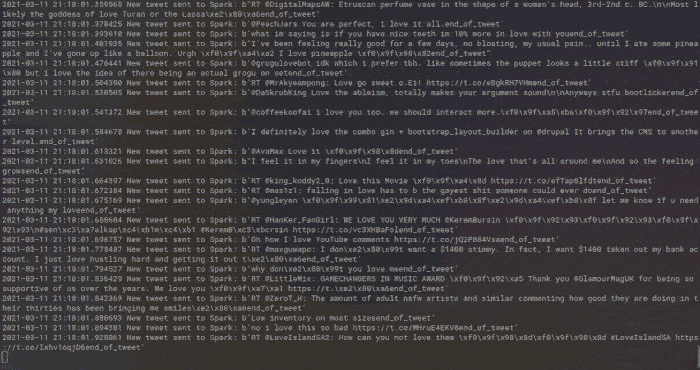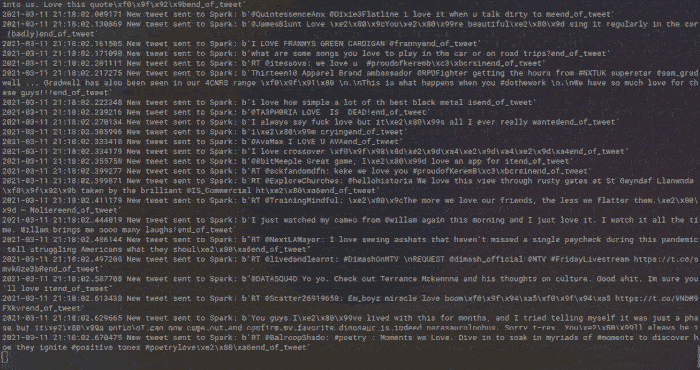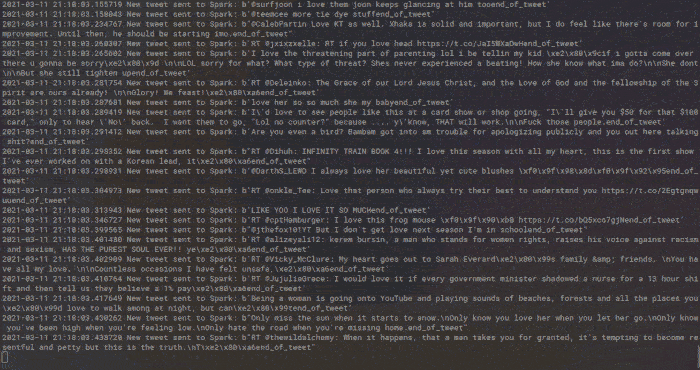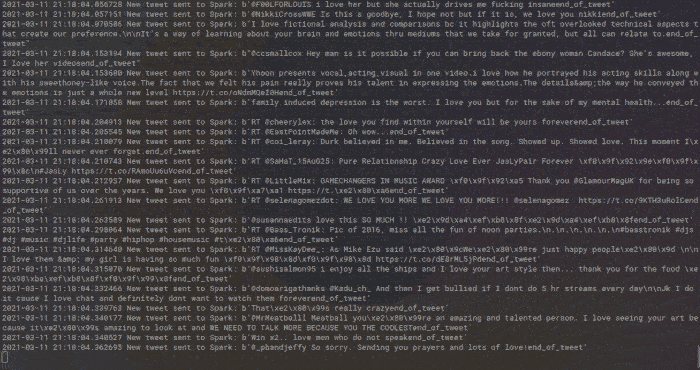
La ventaja de poder subir esta aplicación a un servidor clouding.io es que no necesariamente tenemos que estar con el ordenador encendido mientras se está ejecutando la aplicación. Podemos subirla y dejarla ejecutándose todo el tiempo que queramos, ya que todos los mensajes de Twitter que se analicen acabarán guardados en un CSV en el propio servidor.
Una de las cosas que más me gustan de usar estos servidores es que gracias a su bajo coste y alto rendimiento seremos capaces de escalar nuestras aplicaciones hasta el punto que queramos, y de hecho utilizando podremos crear un clúster de servidores con Apache Spark muy fácilmente.